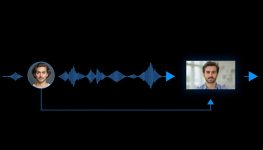
SadTalker là công cụ cho phép bạn đưa một ảnh tĩnh (chân dung) và một file audio (ví dụ lời nói, lời hát) → sinh video nhân vật nói/hát với chuyển động đầu & biểu cảm rất “tự nhiên”. arXiv+1
Điểm nổi bật:
- Sử dụng mô hình 3D để điều khiển biểu cảm & chuyển động đầu, giúp video trông chân thực hơn. arXiv+1
- Có sẵn demo, có thể chạy offline nếu bạn có GPU. GitHub+1
- Được dùng nhiều cho anime, tạo talk-head, chỉnh sửa video talking face.
2. Yêu cầu & chuẩn bị
Trước khi bắt đầu, bạn cần chuẩn bị những điều sau:
a) Phần cứng & môi trường
- Có GPU (nên có ít nhất NVIDIA GPU với CUDA hỗ trợ để chạy tốc độ tốt).
- Python 3.8 (khuyến nghị) để tương thích với version chính. GitHub+1
- ffmpeg được cài để xử lý video/âm thanh. GitHub
- Git để clone repository.
b) File đầu vào
- Ảnh chân dung (source image) hoặc video gốc nếu bạn muốn build từ video.
- File âm thanh (audio file, ví dụ
.wav) mà bạn muốn nhân vật nói/hát theo. - Option: nếu bạn muốn full body, chuyển động đầu, biểu cảm… thì ảnh/video chất lượng càng tốt càng dễ xử lý.
c) Tải code & models
- Clone repository từ GitHub:
git clone https://github.com/OpenTalker/SadTalker.git
``` :contentReference[oaicite:9]{index=9}
- Vào thư mục:
cd SadTalker
- Tải các checkpoint (mô hình đã huấn luyện) theo hướng dẫn trong README.
3. Cài đặt chi tiết
Dưới đây là quy trình cài đặt (ví dụ dùng trên Linux/macOS). Nếu bạn dùng Windows hoặc Docker có chút khác, mình sẽ ghi chú bên dưới.
# tạo môi trường
conda create -n sadtalker python=3.8
conda activate sadtalker
# cài torch + cuda: ví dụ với CUDA 11.3
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
# cài ffmpeg
conda install ffmpeg
# cài các thư viện còn lại
pip install -r requirements.txt
Windows
- Cài Python 3.8, trong khi cài “Add Python to PATH”.
- Cài Git, cài ffmpeg (ví dụ scoop hoặc manual).
- Clone repo rồi chạy batch file
webui.bathoặc theo README. GitHub
Docker / WSL
- Nếu bạn muốn dùng container thì có thể tìm bản Docker image của cộng đồng (ví dụ sadtalker-api) và mount GPU. GitHub
4. Chạy thử cơ bản
Sau khi cài xong, bạn có thể chạy thử như sau:
CLI (dòng lệnh)
python inference.py --driven_audio path/to/audio.wav \
--source_image path/to/image.png \
--enhancer gfpgan
Lệnh trên sẽ lấy ảnh nguồn + audio rồi tạo video ghi tại thư mục results/*. GitHub
Nếu bạn muốn full‐body hoặc chế độ khác:
python inference.py --driven_audio <audio.wav> \
--source_image <video.mp4 or picture.png> \
--result_dir <output_folder> \
--still \
--preprocess full \
--enhancer gfpgan
WebUI / Gradio
- Chạy file
app_sadtalker.pyđể mở giao diện web đơn giản và kéo thả ảnh + audio vào. GitHub - Windows: nhấn đôi
webui.bat. - Mac/Linux:
bash webui.sh.
5. Mẹo & lưu ý khi sử dụng
- Ảnh nguồn nên là mặt rõ, ánh sáng ổn, không quá nghiêng – giúp hệ thống dễ bắt biểu cảm & môi.
- Âm thanh nên rõ lời, ít tạp âm, nếu là lời hát có thể tách lời & loại bỏ nền để khẩu hình đồng bộ tốt hơn.
- Kiểm tra đầu ra: nếu chuyển động đầu bị giật hoặc môi không khớp, thử giảm tốc độ hoặc dùng audio có nhịp ổn hơn.
- Nếu bị lỗi GPU/Out of Memory: có thể giảm kích thước ảnh, giảm batch size hoặc sử dụng mode “still” thay vì full video.
- Tuân thủ bản quyền & quyền nhân vật: nếu ảnh là người thật, cần có quyền sử dụng. README dự án cũng có lưu ý về quyền và sử dụng. GitHub+1
- Cập nhật phiên bản: thường dự án có phiên bản mới hơn với cải tiến biểu cảm & độ phân giải – kiểm tra tag release trên GitHub.






